AI와 도메인 지식 융합, AI 경영 고도화를 위한 방안 자살 의도 감지를 위한 지식 기반 트랜스포머 접근 방식 [2505년 3월 ISR]
KETCH: A Knowledge-Enhanced Transformer-Based Approach to Suicidal Ideation Detection from Social Media Content.
Zhang, Dongsong, Zhou, Lina, Tao, Jie ,Zhu, Tingshao ,Gao, Guodong
Information Systems Research. Mar2025, Vol. 36 Issue 1, p572-599. 28p.

CEO 인사이트
도메인 지식(전문가 어휘집, 핵심 용어)을 AI 모델에 효과적으로 통합함으로써 인간 지능과 인공 지능 간의 시너지를 통해 자살 방지 시스템의 효과를 연구했습니다. 이를 통해 데이터 품질 개선과 정확성을 확보하는 AI활용 사례를 볼 수 있습니다. AI를 통해 인간의 생명을 보존하는 방향으로 활용할 수 있는 사례를 볼 수 있었습니다.
1. 개요 및 중요성
본 연구는 자살 의도(Suicidal Ideation, SI) 감지를 위한 새로운 지식 강화 트랜스포머 기반 접근 방식인 KETCH를 제안, 개발, 평가합니다. 자살 의도는 즉각적인 지원과 개입이 필요한 정신과적 응급 상황이지만, 자살 의도를 겪는 대부분의 사람들은 전문가의 도움을 적극적으로 찾지 않아 돌이킬 수 없는 결과를 초래할 수 있습니다. 소셜 미디어 플랫폼에서 자살 의도를 표현하는 사람들이 증가함에 따라, 소셜 미디어는 자살 의도 감지를 위한 실현 가능한 장소가 되었습니다.
2. 핵심 개념 및 정의
1) 자살 의도(SI)
자살 관련 행동에 참여하려는 생각, 고려, 또는 숙고입니다.
2) 자해(Self-harm)
자신에게 의도적으로 해를 입히거나 상해를 입히는 행위. 이는 정신 질환이라기보다는 개인적인 고통의 표현입니다. 자살 의도가 자해 사례의 28%~41%에서 발견되었지만, 자해 사고의 85% 이상은 생명을 끊으려는 의도보다는 긴장 해소를 주된 목적으로 발생합니다.
3) 우울증(Depression)
사람이 느끼고, 생각하고, 일상 활동을 처리하는 방식에 영향을 미치는 흔하지만 심각한 기분 장애입니다. 자살로 사망한 사람들의 90% 이상이 정신 건강 문제, 특히 우울증을 겪었지만, 대부분의 우울증 환자는 자살로 사망하지 않으며, 많은 이들은 가장 심각한 우울증 시나리오에서도 자살 의도를 경험하지 않습니다.
4) 트랜스포머 기반 모델 (예: BERT, RoBERTa)
자연어 처리(NLP) 작업에서 우수한 성능을 보여왔으며, 문맥적 관계를 학습하기 위한 자체 주의(self-attention) 메커니즘에 의존합니다.
5) 어휘집(Lexicon)
특정 도메인 또는 작업과 관련된 어휘로, 도메인 지식으로 활용됩니다. 본 연구에서는 ‘사회 미디어 지향 자살 의도 어휘집’의 중요성을 강조합니다.
3. 기존 자살 의도 감지(SID) 연구의 한계점
기존 자살 의도 감지 연구는 다음과 같은 한계점을 가지고 있습니다.
1) 전통적인 기계 학습 방법의 한계
많은 모델이 노동 집약적이고 임시적인 특징 공학(feature engineering)을 요구하는 전통적인 기계 학습 방법(예: 의사결정 트리, 로지스틱 회귀)을 사용합니다.
2) 정적 텍스트 표현 및 트랜스포머 모델 활용 부족
최근 딥러닝 기법이 탐색되었지만, 주로 정적 텍스트 표현을 사용하는 기존 딥러닝 모델을 채택했습니다. BERT와 같은 트랜스포머 기반 모델은 NLP 작업에서 우수한 성능을 보였지만, 자살 의도 감지에는 충분히 연구되지 않았습니다.
3) 도메인 지식(어휘집)의 간과
기존 자살 의도 감지 모델의 대부분은 데이터 기반이며 도메인 지식(예: 도메인 어휘집)을 간과합니다. 어휘집을 통합한 일부 연구도 일반적이거나 주변적인 어휘집(예: 일반적인 감정 어휘집)을 사용했으며, 특히 소셜 미디어 콘텐츠를 위해 설계된 핵심 도메인별 어휘집은 사용하지 않았습니다.
4) 임베딩 및 어휘집 정렬 문제
기존 모델들은 어휘집을 어휘집 훈련된 언어 모델에서 학습된 텍스트 임베딩과 단순히 연결하지만, 이러한 임베딩이 어휘집 용어의 표현 세분화와 일치하지 않을 수 있습니다.
5) 모델 견고성 및 일반화 가능성 평가 부족
대부분의 기존 자살 의도 감지 연구는 여러 데이터 세트에서 다양한 언어(사용자 및 게시물 수준 모두)에 걸쳐 모델 성능을 평가하지 않아 모델의 견고성과 일반화 가능성에 대한 불확실성을 야기합니다.
4. 지식 기반 트랜스포머 접근 방식(KETCH)의 주요 설계 및 혁신
지식 기반 트랜스포머 접근 방식(knowledge-enhanced transformer-based approach, KETCH)는 이러한 한계점을 해결하기 위해 다음과 같은 주요 구성 요소를 포함합니다:
1) 텍스트 전처리(Text Preprocessing)
데이터 정제 및 토큰화를 포함하며, 중국어와 영어와 같이 언어에 따라 토큰화 방식이 다릅니다.
2) 지식 융합을 통한 표현 정제(Representation Refinement via Knowledge Fusion)
RoBERTa의 자체 주의 메커니즘을 활용하여 소셜 미디어 게시물의 일반적인 텍스트 표현을 학습합니다. 사전 훈련된 RoBERTa 모델의 일반적인 텍스트 표현이 자살 의도 텍스트의 언어적 미묘함을 포착하지 못할 수 있다는 점을 고려하여, 자살 의도 유무를 나타내는 소셜 미디어 게시물을 사용하여 RoBERTa 모델의 매개변수를 업데이트하여 도메인별 텍스트로 표현을 정제합니다.
"KETCH leverages RoBERTa’s self-attention mechanism to learn the representation of social media posts(KETCH는 소셜 미디어 게시물의 표현을 학습하기 위해 RoBERTa의 자체 주의 메커니즘을 활용합니다.)."
"Given that text representation from the pretrained RoBERTa model is generic and may not capture linguistic intricacies in the SI text, we refine the text representation with domain-specific text(사전 훈련된 RoBERTa 모델에서 얻은 텍스트 표현은 일반적이며 자살 의도 텍스트의 언어적 미묘함을 포착하지 못할 수 있으므로, 도메인 특화 텍스트로 텍스트 표현을 정제합니다)."
3) 모델 정렬을 통한 표현 강화(Representation Enhancement via Model Alignment)
전문가가 큐레이션한 자살 의도 어휘집을 구축하는 5단계 절차를 따릅니다. 이 어휘집은 자살 의도와 관련된 핵심 용어와 표현을 포괄하며, 특히 소셜 미디어 맥락에 적합하도록 설계되었습니다. (예: 320개의 중국어 자살 의도 용어로 구성된 어휘집)
"The construction of a social media–oriented and expert-curated domain lexicon comprises five main steps: (1) Defining the target domain and collecting a representative corpus; (2) Identifying seed terms; (3) Refining seed terms; (4) Expanding seed terms; (5) Pruning the expanded terms.(소셜 미디어 기반의 전문가 큐레이션 도메인 어휘집 구축은 다음 다섯 가지 주요 단계로 이루어집니다: (1) 대상 도메인 정의 및 대표 코퍼스 수집; (2) 시드 용어 식별; (3) 시드 용어 정제; (4) 시드 용어 확장; (5) 확장된 용어 정리)."
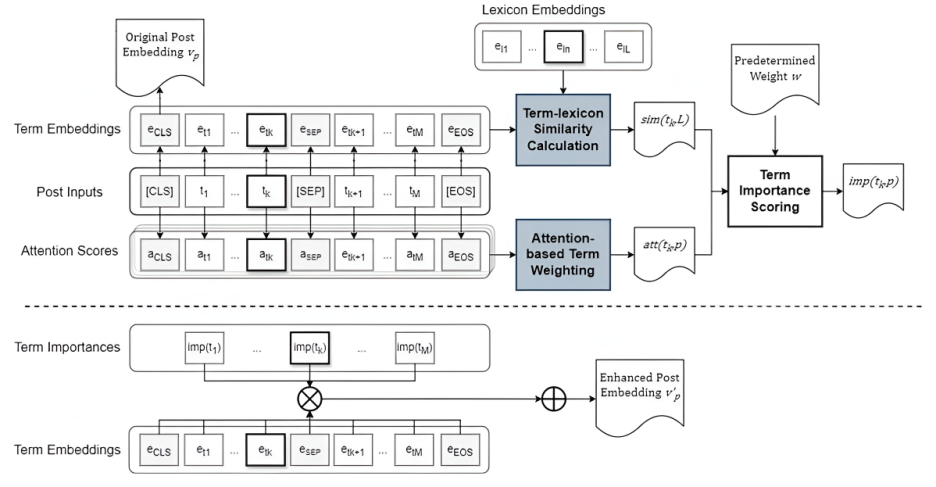
4) 정렬된 동적 임베딩
용어의 맥락적 중요성을 결정하기 위해 RoBERTa의 마지막 q 레이어(최적 q 값은 4)에서 주의 점수(attention score)를 추출하여 개별 용어 수준으로 확장합니다. 이는 동일한 게시물 내에서 용어를 차별화하고 다른 맥락에서 동일한 용어의 다른 의미를 반영하도록 임베딩을 수정하여 용어 표현의 더 나은 맥락화를 가능하게 합니다.
"Aligned dynamic embedding for term representation determines the contextual importance of term t to post p(정렬된 동적 임베딩을 이용한 용어 표현은 특정 용어(t)가 게시물(p)에 대해 갖는 문맥적 중요성을 결정합니다.)."
"To address the above limitation, the aligned dynamic embedding drills down to the level of individual terms by extending term (or token) embeddings to incorporate dynamic term-level attention in p, att (t, p)(위의 한계를 해결하기 위해, 정렬된 동적 임베딩은 개별 용어(또는 토큰) 임베딩을 확장하여 게시물(p) 내에서 동적인 용어 수준 주의(att(t, p))를 포함함으로써 개별 용어 수준으로 깊이 들어갑니다.)."
5) 어휘집 기반 강화
용어(t)의 자살 의도 관련성을 측정하기 위해 어휘집(L)의 용어(l)와의 유사성(sim(t, L))을 통합합니다. 이는 용어 임베딩과 어휘집 용어 임베딩 간의 코사인 유사성을 기반으로 합니다.
6) 용어 중요도(imp(t,p))
용어-어휘집 유사성(sim(t, L))과 동적 용어 수준 주의(att(t, p))의 가중 합으로 정의되어, 도메인 관련성과 맥락적 중요성을 모두 고려합니다.
imp(t, p) = w × sim(t, L) + (1−w) × att(t, p)
(여기서 w는 가중치이며, 최적 값은 0.6으로 판명되었습니다.)
이러한 접근 방식은 자살 의도 어휘집 용어가 게시물 표현에 더 큰 영향을 미치도록 하고, 동시에 어휘집에 없는 용어라도 맥락적 중요성이 높으면 자살 의도 감지에 기여할 수 있도록 합니다.
5. KETCH의 평가 및 결과
연구는 두 가지 언어(중국어, 영어)와 두 가지 플랫폼(Sina Weibo, Reddit)의 소셜 미디어 데이터를 사용하여 KETCH의 성능을 평가했습니다.
1) 성능 우수성
KETCH는 정밀도(Precision), 재현율(Recall), F1 점수, 정확도(Accuracy) 등 모든 성능 지표에서 모든 기준 모델(12개)을 일관되게 능가했습니다. 특히, 어휘집 훈련된 RoBERTa 모델에 표현 정제(RR), SMOTE (SM) 및 표현 강화(RE)를 통합하면서 성능이 점진적으로 향상됨을 보여주었습니다.
"KETCH consistently outperforms all baseline models across performance measures(KETCH는 모든 성능 측정 지표에서 모든 기준 모델을 일관되게 능가했습니다)."
2) 어휘집 기반 강화 및 정렬된 동적 임베딩의 효과
민감도 분석 결과, w = 0.6일 때 KETCH가 최상의 성능을 달성했으며, 이는 어휘집 기반 강화와 정렬된 동적 임베딩 모두가 자살 의도 감지 성능 향상에 기여함을 시사합니다.
"When w = 0.6, KETCH achieves the best performance. In other words, models integrating both lexicon-based enhancement and aligned dynamic embedding outperform those incorporating either of them alone(w = 0.6일 때 KETCH가 최고의 성능을 달성합니다. 다시 말해, 어휘 기반 강화와 정렬된 동적 임베딩을 모두 통합한 모델이 둘 중 하나만 통합한 모델보다 뛰어난 성능을 보입니다)."
전문가 큐레이션 자살 의도 어휘집(CSI/ESI)이 ChatGPT 생성 어휘집(GPT-CSI/GPT-ESI)이나 주변 어휘집(NRC VAD)보다 효과적임을 입증했습니다. 이는 어휘집 구축 방법보다는 어휘집의 전반적인 품질, 관련성, 적합성(핵심 대 주변)이 모델 성능에 더 중요하다는 것을 시사합니다.
3) 견고성 (사용자 수준 모델 및 다양한 게시물 수)
KETCH는 게시물 수준 모델뿐만 아니라 사용자 수준 모델(사용자의 과거 게시물 통합)에서도 우수한 성능을 보여주었습니다. 사용자 수준 모델에서 게시물 통합 방법 중 평균화(averaging) 방법이 연결(concatenation) 및 앙상블(ensemble) 방법보다 일반적으로 우수했습니다.
사용자당 게시물 수(1~5개)에 따라 모델 성능의 명확한 패턴은 없었으며, KETCH는 다른 사용자 그룹 간에 성능 차이가 유의미하지 않아 견고함을 입증했습니다.
4) 일반화 가능성 (우울증 감지)
KETCH는 자살 의도 감지 외에 우울증 감지에도 적용 가능함을 보여주었으며, 이는 다른 정신 건강 문제 감지에도 KETCH가 적용될 수 있음을 시사합니다.
6. KETCH의 실용적 함의 및 연구 기여
1) 시의적절한 개입
KETCH는 자살 의도의 조기 및 시의적절한 감지를 위한 실질적인 기회를 제공하여, 잠재적으로 공중 보건, 경제, 사회에 광범위한 영향을 미칠 수 있습니다. KETCH-활성화 온라인 개입(KOI)에 대한 현장 연구는 어휘집 예방적 접촉, 개인 정보 보호, 적시 지원에 대한 사용자 수용도가 높음을 보여주었습니다.
2) 인간 지능과 기계 지능의 시너지
KETCH는 도메인 지식을 AI 모델에 효과적으로 통합함으로써 인간 지능과 기계 지능 간의 시너지를 입증합니다.
3) 다국어 및 다수준 환경에서의 유효성
중국어와 영어 소셜 미디어 게시물을 포함하고, 게시물 수준과 사용자 수준 모두에서 평가되었으며, 자살 의도 및 우울증 감지 등 다양한 문제를 포함하는 다국어 및 다수준 실험 설정은 KETCH의 광범위한 적용 가능성을 강조합니다.
4) 다른 NLP 작업으로의 확장 가능성
KETCH의 전반적인 방법론적 설계, 특히 도메인 어휘집을 트랜스포머 기반 모델에 통합하는 접근 방식은 도메인 지식의 이점을 얻을 수 있는 다른 NLP 작업(예: 다른 정신 질환 또는 공격적인 콘텐츠 감지)에도 적용할 수 있습니다.
7. 한계 및 향후 연구 방향
1) 멀티모달 표현
현재 KETCH는 텍스트 콘텐츠에만 초점을 맞춥니다. 향후 연구는 소셜 미디어 게시물의 멀티모달 표현(예: 텍스트와 이미지 모두)을 활용하여 감지 모델의 효과를 향상시킬 수 있습니다.
2) 어휘집 업데이트 및 설계 지침
소셜 미디어 기반 어휘집은 자살 의도 소셜 미디어 게시물에서 사용되는 용어 및 표현에 상당한 변화가 있을 때 주기적인 업데이트가 필요할 수 있습니다. 핵심 어휘집 내 용어의 양과 질이 KETCH 성능에 영향을 미치므로, 향후 연구에서는 이러한 요인에 대한 설계 지침을 개발하는 것이 좋습니다.
KETCH 활성화 온라인 개입에 대한 현장 연구는 타당성 탐색에 중점을 두었으며, KETCH의 감지 성능을 재평가하는 데는 아니었습니다. KETCH 활성화 온라인 개입에 대한 엄격한 평가는 향후 연구가 필요한 복잡하고 별도의 연구 문제입니다.
3) 데이터 세트 한계 및 개인 정보
Sina Weibo 데이터 세트는 게시물 시각이 부족하여 자살 의도 발생 시 경과 시간의 영향을 분석할 수 없었습니다. 또한, 사용자 개인 정보를 고려하여 현장 연구에서 사용자 인구 통계 정보를 수집하지 않았습니다. 향후 연구에서는 사용자 인구 통계 정보를 수집하거나 추론하여 KETCH의 견고성을 다른 인구 통계학적 특성을 가진 사용자 하위 그룹에 대해 조사할 수 있습니다.
4) 인간 편향 완화
전문가 큐레이션 어휘집 구축 과정에서 인간의 편향과 불일치가 발생할 수 있습니다. 본 연구에서는 전문가에게 전문 교육을 제공하고, 각 단계에 최소 3명의 전문가를 참여시키고, 상호 평가자 신뢰도와 다수결 투표를 구현하는 등 여러 조치를 사용하여 이러한 편향을 완화했습니다. 향후 연구에서는 어휘집 구축에서 인간 편향 및 변동을 완화하기 위한 공식적인 방법을 탐색해야 합니다.
묻고 답하기
1. 자살 의도(SI)란 무엇이며, 소셜 미디어를 통한 자살 의도 감지(SID)가 왜 중요한가요?
자살 의도(SI)는 자살 관련 행동에 대한 생각, 고려 또는 숙고를 의미하며, 자살 계획, 자살 시도, 자살 완료로 이어지는 4단계 자살 과정의 시작점입니다. 자살 의도는 심리적 응급 상황으로 즉각적인 지원과 개입이 필요하지만, 대부분의 자살 의도를 겪는 사람들은 정신 건강 전문가의 도움을 적극적으로 구하지 않습니다.
최근 연구에 따르면, 자살 의도를 겪는 사람들은 소셜 미디어 플랫폼에 자신의 생각과 감정을 점점 더 많이 표현하고 있으며, 이로 인해 소셜 미디어가 자살 의도를 감지하기 위한 중요한 수단으로 떠오르고 있습니다. 소셜 미디어는 대규모 사용자 생성 콘텐츠를 제공하여 적시에 자살 의도를 감지하고 선제적인 개입을 할 수 있는 실질적인 기회를 제공하며, 이는 공중 보건, 경제 및 사회에 광범위한 영향을 미칠 수 있습니다.
2. 기존의 자살 의도 감지(SID) 연구에는 어떤 한계점이 있었나요?
기존 자살 의도 감지 연구에는 몇 가지 주요 한계점이 있었습니다. 첫째, 많은 모델이 수작업의 특징 엔지니어링이 필요한 의사 결정 트리 및 로지스틱 회귀와 같은 전통적인 기계 학습 방법을 사용했습니다. 최근 딥러닝 기술이 탐구되었지만, 주로 정적 텍스트 표현을 사용하는 기존 딥러닝 모델에 머물렀습니다. BERT(Bidirectional Encoder Representations from Transformers)와 같은 트랜스포머 기반 모델은 자연어 처리(NLP) 작업에서 뛰어난 성능을 보였음에도 불구하고 자살 의도 감지 분야에서는 충분히 연구되지 않았습니다.
둘째, 대부분의 기존 자살 의도 감지 모델은 데이터 기반으로만 작동하여 도메인 지식(예: 도메인 어휘집)의 중요한 역할을 간과했습니다. 일부 연구에서 어휘집(lexicons)을 딥러닝 모델에 통합했지만, 자살 의도 감지에 특화된 핵심 도메인별 어휘집보다는 일반적이거나 주변적인 어휘집(예: 일반 감성 어휘집)을 사용했습니다. 특히, 기존 연구들은 소셜 미디어 콘텐츠에 특화된 자살 관련 키워드 목록이나 어휘집을 설계하지 않았으며, 주로 키워드 매칭 방식에 의존하여 비효율적일 수 있었습니다.
셋째, 기존 모델들은 어휘집과 어휘집 훈련된 언어 모델에서 학습된 텍스트 임베딩을 단순히 연결하는 경향이 있었지만, 어휘집 훈련된 모델에서 직접 얻은 임베딩은 표현 세분화 측면에서 어휘집 용어의 임베딩과 일치하지 않을 수 있었습니다.
넷째, 현재까지 소수의 자살 의도 감지 연구만이 사용자 및 게시물 수준에서 여러 언어의 여러 데이터 세트에 걸쳐 모델 성능을 평가하여 모델 견고성과 일반화 가능성에 대한 불확실성이 있었습니다. 이러한 연구 격차와 도전 과제는 도메인 지식을 트랜스포머 모델에 통합하여 자살 의도 감지를 개선하기 위한 새로운 정보 기술(IT) 아티팩트를 설계하도록 동기를 부여했습니다.
3. KETCH(Knowledge-Enhanced Transformer-Based Approach)는 기존 자살 의도 감지 모델의 한계를 어떻게 극복하나요?
KETCH는 기존 자살 의도 감지 모델의 한계를 극복하기 위해 다음과 같은 새로운 설계 요소를 포함합니다.
1) 사회 미디어 지향 자살 의도 어휘집
소셜 미디어 콘텐츠의 특성을 반영하여 특별히 구성된 자살 의도 어휘집을 사용합니다. 이는 일반적인 어휘집이나 의료 전문 용어 어휘집의 한계를 극복합니다.
2) 도메인 지식 통합
최첨단 트랜스포머 모델에 도메인 지식(예: 어휘집)을 통합하기 위한 모델 수준의 방법을 제시합니다. 이는 단순히 입력을 연결하는 것을 넘어, 모델의 표현 학습 과정에 지식을 깊이 있게 반영합니다.
3) 정렬된 동적 임베딩 및 어휘집 기반 강화
용어의 도메인 관련성과 문맥적 중요성을 효과적인 자살 의도 감지에 통합합니다. 이를 통해 KETCH는 어휘집 용어와 사회 미디어 게시물의 의미론적 유사성뿐만 아니라 게시물 내에서 용어의 동적인 문맥적 중요성을 동시에 고려하여 표현을 강화합니다.
4) 다중 언어 및 다단계 평가
두 가지 다른 플랫폼에서 수집된 두 가지 다른 언어의 소셜 미디어 데이터를 사용하여 KETCH의 성능을 평가하고, 자살 위험 예측 및 우울증 감지를 위한 사용자 수준 모델로의 일반화 가능성을 추가로 조사하여 모델의 견고성과 일반화 가능성을 입증합니다.
4. KETCH 모델의 주요 구성 요소는 무엇이며, 어떻게 작동하나요?
KETCH 모델은 다음과 같은 네 가지 주요 구성 요소로 구성됩니다.

1) 텍스트 전처리 (Text Preprocessing)
데이터 정제 및 토큰화를 포함합니다. 예를 들어, 중국어 토큰화는 한자를 단어로 분할하는 반면, 영어 토큰화는 일반적으로 단어에서 구두점을 분리합니다.
2) 지식 융합을 통한 표현 정제 (Representation Refinement via Knowledge Fusion)
RoBERTa와 같은 어휘집 훈련된 트랜스포머 모델을 활용하여 일반적인 텍스트 표현을 학습합니다. 이 모델은 셀프 어텐션 메커니즘을 사용하여 단어 간의 문맥적 관계를 학습하고, 아웃오브보캐블러리(out-of-vocabulary) 문제를 효과적으로 해결합니다. 자살 의도 텍스트의 언어적 미묘함을 포착하기 위해 자살 의도 유무에 관계없이 소셜 미디어 게시물을 사용하여 RoBERTa 모델의 매개변수를 업데이트하여 텍스트 표현을 도메인에 맞게 정제합니다.
3) 모델 정렬을 통한 표현 강화 (Representation Enhancement via Model Alignment)
이 부분은 KETCH의 핵심적인 혁신으로, 두 가지 주요 구성 요소를 통해 작동합니다.
(1) 정렬된 동적 임베딩 (Aligned Dynamic Embedding)
RoBERTa의 셀프 어텐션 메커니즘에서 얻은 동적 용어 수준 어텐션(attention)을 통합하여 개별 용어의 문맥적 중요성을 결정합니다. 이는 단순히 마지막 레이어의 출력을 사용하는 것을 넘어, 특정 용어가 게시물 내에서 다른 용어에 얼마나 중요하게 작용하는지 동적으로 포착합니다.
(2) 어휘집 기반 강화 (Lexicon-based Enhancement)
자살 의도 어휘집과의 용어-어휘집 유사성(term-lexicon similarity)을 측정하여 해당 용어가 자살 의도와 얼마나 관련이 있는지를 정량화합니다. 이 두 구성 요소를 결합하여 게시물 내 특정 용어(토큰)가 자살 의도 예측에 얼마나 중요한지(imp(t, p))를 결정하며, 이를 통해 게시물의 강화된 표현(v'p)을 생성합니다.
4) 분류 (Classification)
강화된 게시물 표현을 입력으로 사용하여 소셜 미디어 게시물이 자살 의도를 포함하는지 여부를 결정하는 분류 모델을 구축합니다. 최적의 성능을 위해 자동화된 기계 학습 기술인 TPOT(Tree-based Pipeline Optimization Tool)를 사용하여 최적의 하이퍼파라미터와 모델 앙상블을 선택합니다.
5. KETCH가 기존 모델들에 비해 어떤 성능 우위를 보였나요?
KETCH는 광범위한 경험적 평가와 현장 연구를 통해 기존 모델들에 비해 다음과 같은 뛰어난 성능 우위, 견고성 및 일반화 가능성을 입증했습니다.
1) 최고의 성능
Ablation 실험 결과, KETCH(RB + RR + SM + RE)는 정밀도(Precision), 재현율(Recall), F1 점수(F1 Score), 정확도(Accuracy)의 모든 측정 지표에서 가장 높은 성능을 보였습니다. 이는 표현 정제(RR)와 표현 강화(RE) 구성 요소가 모델 성능 향상에 크게 기여했음을 시사합니다.
2) 어휘집 통합의 중요성
어휘집 기반 강화와 정렬된 동적 임베딩(문맥적 중요성)을 모두 통합한 모델이 둘 중 하나만 통합한 모델보다 뛰어난 성능을 달성했습니다. 특히, KETCH는 w=0.6일 때 가장 좋은 성능을 보여주며, 어휘집 용어 유사성과 문맥적 중요성 모두가 자살 의도 감지에 긍정적인 영향을 미침을 입증했습니다.
3) 전문가 큐레이팅 어휘집의 우위
ChatGPT로 생성된 어휘집(GPT-CSI/GPT-ESI)이나 주변적인 NRC VAD 어휘집보다 전문가가 큐레이팅한 중국어 자살 의도 어휘집(CSI) 및 영어 자살 의도 어휘집(ESI)을 사용한 KETCH가 더 효과적이었습니다. 이는 도메인에 특화된 고품질 어휘집의 중요성을 강조합니다.
4) 언어 및 게시물 유무에 따른 견고성
KETCH는 어휘집 용어를 포함하는 게시물에서 더 나은 성능을 보였지만, 어휘집 용어가 없는 게시물에서도 여전히 합리적이고 일관된 성능을 유지했습니다. 이는 KETCH가 다양한 유형의 소셜 미디어 콘텐츠에 대해 견고함을 시사합니다.
사용자 수준 모델로의 일반화: KETCH는 게시물 수준 모델뿐만 아니라 사용자 수준 모델(예: Reddit 데이터 세트를 사용한 자살 위험 예측)에서도 효과적인 성능을 보여주었습니다. 특히, 다중 게시물 집계 방법 중 '평균' 방식이 '연결' 및 '앙상블' 방식보다 일반적으로 우수하다는 것을 발견했습니다.
5) 다른 정신 건강 문제로의 일반화
KETCH는 우울증 감지(Reddit Self-Reported Depression Diagnosis (RSDD) 데이터 세트 사용)와 같은 다른 유형의 정신 건강 문제에도 잘 적용되고 일반화될 수 있음을 보여주었습니다.
6. KETCH 모델 구축에 사용된 데이터 세트는 무엇이며, 어떻게 수집되었나요?
KETCH 모델의 평가를 위해 두 가지 소셜 미디어 데이터 세트가 수집되었습니다.
1) 중국어 Sina Weibo 데이터 세트
- 출처: 중국에서 두 번째로 큰 소셜 미디어 플랫폼인 Sina Weibo에서 수집되었습니다.
- 수집 방법: 2012년 우울증으로 자살한 개인이 만든 Sina Weibo 그룹과 관련된 29,388명의 사용자로부터 104,219개의 게시물을 크롤링했습니다. 이 게시물들은 2016년 1월 1일부터 2018년 7월 24일 사이에 생성되었습니다.
- 전처리 및 레이블링: 5개 미만의 중국어 단어를 포함하는 게시물을 제외한 99,030개의 게시물을 얻었으며, 이들을 훈련(89,126개, 14,342개 자살 의도 게시물 포함) 및 테스트(9,904개, 1,581개 자살 의도 게시물 포함) 데이터로 무작위로 계층화했습니다. 6명의 도메인 전문가(정신과 의사 등)가 각 게시물을 독립적으로 수동으로 자살 의도 여부를 레이블링했으며, 3명의 전문가가 각 게시물에 레이블을 부여했습니다. Krippendorff's alpha로 측정된 평가자 간 신뢰도는 0.83이었습니다.
- 중국어 자살 의도 어휘집 구축: 4,600개 이상의 Sina Weibo 게시물(확인된 자살 사용자 및 기타 활성 사용자로부터)을 수집하여 사회 미디어 지향 및 전문가 큐레이팅된 중국어 자살 의도 어휘집을 구축했습니다. 이 어휘집은 자살 연구 전문가 패널에 의해 시드 용어를 정의하고, 정제하고, 확장하는 5단계 절차를 거쳐 최종적으로 320개의 자살 의도 용어로 구성되었습니다. 이 과정에서 인간의 편향을 완화하기 위해 여러 조치가 취해졌습니다.
2) 영어 Reddit 데이터 세트
- 출처: Reddit의 자살 관련 서브레딧과 컨트롤 서브레딧에서 수집되었습니다.
- 수집 방법: Reddit 자살 데이터 세트 버전 2(University of Maryland, American Association of Suicidology 제공)를 활용했습니다.
- 목적: 주로 KETCH의 사용자 수준 모델에 대한 견고성 확인 및 다른 언어(영어) 데이터로의 일반화 가능성을 평가하는 데 사용되었습니다.
- 이 두 데이터 세트의 사용은 KETCH 모델의 다국어 및 다단계 평가를 가능하게 하여 모델의 견고성과 일반화 가능성을 강력하게 뒷받침합니다.
7. KETCH가 자살 의도 감지 외에 다른 정신 건강 문제 감지에도 활용될 수 있나요?
KETCH는 자살 의도 감지 외에도 다른 정신 건강 문제 감지에도 활용될 수 있음을 입증했습니다. 본 연구는 KETCH의 일반화 가능성을 평가하기 위해 우울증 감지에 KETCH를 적용했습니다.
- 데이터 세트: Reddit Self-Reported Depression Diagnosis (RSDD) 데이터 세트(Yates et al., 2017)를 사용했습니다. 이 데이터 세트에는 9,210명의 진단된 우울증 사용자와 107,274명의 대조군 사용자가 포함되어 있으며, 각 사용자당 평균 969개의 게시물이 있습니다.
- 결과: MentalRoBERTa로 학습된 텍스트 표현을 사용하는 KETCH 모델은 기존 우울증 감지 모델(Yates et al., 2017 모델 및 미세 조정된 MentalRoBERTa 모델)보다 높은 정밀도, 재현율, F1 점수를 달성했습니다. 특히, 미세 조정된 MentalRoBERTa 모델보다 훨씬 높은 재현율과 F1 점수를 보였습니다.
이러한 결과는 KETCH의 방법론적 설계, 특히 도메인 어휘집을 트랜스포머 기반 모델에 통합하는 접근 방식이 자살 의도 감지뿐만 아니라 다른 자연어 처리(NLP) 작업, 예를 들어 다른 정신 질환이나 공격적인 콘텐츠 감지에도 적용될 수 있음을 시사합니다. 이는 KETCH가 다양한 정신 건강 문제 감지에 대한 광범위한 적용 가능성과 일반화 가능성을 가지고 있음을 강력하게 보여줍니다.
8. KETCH 연구의 주요 한계점과 향후 연구 방향은 무엇인가요?
KETCH 연구는 중요한 기여를 했지만, 몇 가지 한계점과 향후 연구 방향이 존재합니다.
1) 주요 한계점
- 텍스트 콘텐츠에만 초점: KETCH는 대부분의 기존 연구와 마찬가지로 소셜 미디어 게시물의 텍스트 콘텐츠에만 초점을 맞춥니다. 이는 이미지와 같은 다른 형태의 정보(멀티모달 표현)를 간과합니다.
- 어휘집 업데이트의 필요성: 사회 미디어 기반 어휘집(예: 중국어 자살 의도 어휘집)은 소셜 미디어 게시물에서 사용되는 용어와 표현의 중요한 변화에 따라 모델의 효과를 유지하기 위해 주기적인 업데이트가 필요할 수 있습니다.
- 현장 연구의 범위: KETCH 활성화 온라인 개입(KOI)에 대한 현장 연구의 주요 목적은 타당성을 탐색하는 것이었으며, KETCH의 감지 성능을 엄격하게 재평가하는 것은 아니었습니다. 따라서 KETCH 활성화 온라인 개입에 대한 엄격한 평가는 향후 더 정교한 설계와 통제가 필요한 복잡하고 별개의 연구 문제입니다.
- 데이터 세트의 한계: Sina Weibo 데이터 세트는 게시물 순서를 유지하지만, 특정 게시물 타임스탬프가 부족하여 자살 의도 발생에 대한 경과 시간의 영향을 분석할 수 없었습니다. 또한 사용자 개인 정보 보호를 위해 현장 연구에서 사용자 인구 통계 정보를 수집하지 않았습니다.
- 인간 편향 및 불일치 가능성: 전문가 큐레이팅 어휘집 구축 과정에서 인간의 편향과 불일치가 발생할 수 있습니다. 다른 전문가 패널을 사용하면 어휘집이 약간 다를 수 있습니다.
2) 향후 연구 방향
- 멀티모달 표현 통합: 텍스트와 이미지를 포함한 소셜 미디어 게시물의 멀티모달 표현을 활용하여 감지 모델의 효과를 높이는 연구가 필요합니다.
- 어휘집 업데이트 및 설계 지침 개발: 핵심 어휘집 내 용어의 양과 품질이 KETCH 성능에 영향을 미치므로, 이러한 요인에 대한 설계 지침을 개발하는 것이 좋습니다.
- KETCH 활성화 온라인 개입에 대한 엄격한 평가: 더 정교한 설계와 통제를 통한 엄격한 평가 연구가 필요합니다.
- 사용자 인구 통계 정보 분석: 사용자 인구 통계 정보를 직접 수집하거나 간접적으로 추론하여, 다른 인구 통계학적 특성을 가진 사용자 하위 그룹에 대한 KETCH의 견고성을 분석하고, 시간에 따른 자살 의도 사용자 그룹의 정신 상태 변화 및 개입의 긴급성 예측에 대한 통찰력을 얻는 연구가 필요합니다.
- 인간 편향 완화 방법 탐색: 어휘집 구축 과정에서 인간의 편향과 변형을 완화하기 위한 공식적인 방법을 탐색해야 합니다.
핵심 용어
- 자살 의도 (SI): 자살과 관련된 행동을 생각하거나 고려하는 것.
- 자살 의도 감지 (SID): 소셜 미디어 콘텐츠에서 자살 관념의 징후를 식별하는 프로세스.
- KETCH: 소셜 미디어 콘텐츠에서 자살 의도 감지를 위한 지식 강화 트랜스포머 기반 접근 방식.
- 트랜스포머 기반 모델: 단어 임베딩의 맥락적 관계를 학습하기 위해 자체 주의 메커니즘을 사용하는 딥 러닝 모델 (예: BERT, RoBERTa).
- 도메인 지식: 특정 분야나 주제에 특화된 지식. 이 연구에서는 자살 관념과 관련된 용어와 표현에 대한 지식.
- 어휘집: 특정 도메인에 특화된 단어와 구의 집합.
- 소셜 미디어 지향 자살 의도 어휘집: 소셜 미디어 콘텐츠에서 사용되는 자살 관념 관련 표현에 초점을 맞춰 전문가가 선별한 어휘집.
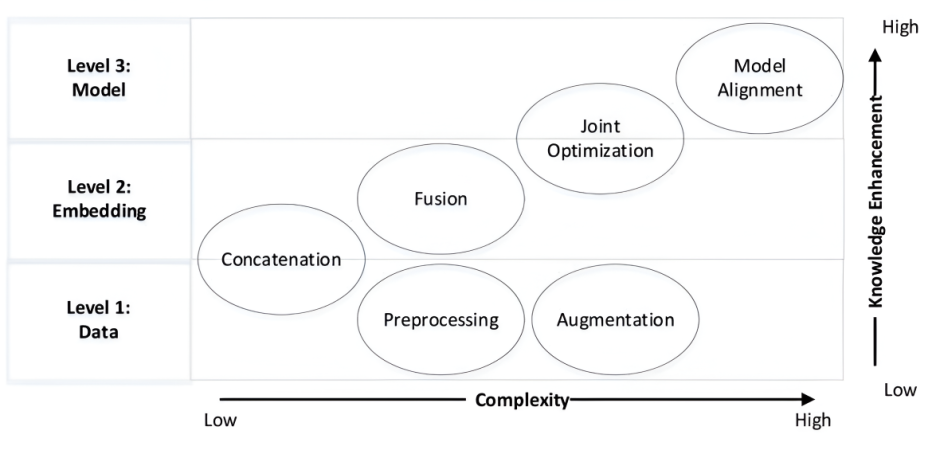
- 데이터 수준 지식 통합: 전처리 또는 입력 텍스트 및/또는 메타 기능 증강에 지식을 사용하는 방법.
- 임베딩 수준 지식 통합: 임베딩을 정제하거나 풍부하게 하는 데 지식을 적용하는 방법 (예: 연결, 융합, 공동 최적화).
- 모델 수준 지식 통합: 텍스트 표현 학습을 위한 모델 아키텍처 설계를 개선하는 데 지식을 가이드로 사용하는 방법.
- RoBERTa: Google의 BERT 모델을 기반으로 최적화된 로버스트한 어휘집 훈련 접근 방식인 트랜스포머 모델.
- 표현 정제: KETCH에서 RoBERTa 모델을 도메인별 텍스트로 미세 조정하여 자살 의도 관련성을 개선하는 단계.
- 표현 강화: KETCH에서 정렬된 동적 임베딩 및 어휘집 기반 강화를 통해 텍스트 표현을 개선하는 단계.
- 정렬된 동적 임베딩: 개별 용어 수준에서 동적 용어 수준 주의를 통합하여 게시물에 대한 용어의 맥락적 중요성을 결정하는 방법.
- 어휘집 기반 강화: 용어와 자살 의도 어휘집 간의 유사도를 측정하여 용어의 자살 의도 관련성을 통합하는 방법.
- 용어 중요성 (imp(t, p)): 게시물 (p)에서 용어 (t)가 자살 의도 예측에 얼마나 중요한지 나타내는 지표. 용어-어휘집 유사도와 동적 용어 수준 주의의 가중 합으로 정의됩니다.
- 게시물 수준 모델: 개별 소셜 미디어 게시물에서 자살 의도를 감지하는 데 중점을 둔 모델.
- 사용자 수준 모델: 사용자의 과거 게시물을 집계하여 자살 의도 위험 정도를 예측하는 데 중점을 둔 모델.
- 연결 (Concatenation): 사용자 수준 모델에서 여러 게시물을 하나의 긴 텍스트 시퀀스로 결합하는 집계 방법.
- 평균 (Averaging): 사용자 수준 모델에서 여러 게시물의 임베딩을 평균화하여 단일 사용자 표현을 생성하는 집계 방법.
- 앙상블 (Ensemble): 사용자 수준 모델에서 여러 게시물 모델의 예측을 결합하는 집계 방법 (예: 사용자의 마지막 N개 게시물 중 하나라도 자살 의도로 감지되면 사용자를 자살 의도 위험으로 예측).
- TPOT (Tree-based Pipeline Optimization Tool): 모델 최적화를 위해 머신러닝 알고리즘과 유전 프로그래밍을 사용하는 자동화된 머신러닝 기술.
- 정밀도 (Precision): 모델이 긍정이라고 예측한 사례 중 실제로 긍정인 사례의 비율.
- 재현율 (Recall): 실제로 긍정인 모든 사례 중 모델이 긍정으로 올바르게 식별한 사례의 비율.
- F1 점수 (F1 Score): 정밀도와 재현율의 조화 평균으로, 두 측정 지표의 균형을 나타냅니다.
- 정확도 (Accuracy): 전체 사례 중 모델이 올바르게 예측한 사례의 비율.
- 코사인 유사도 (Cosine Similarity): 두 벡터의 유사성을 측정하는 방법으로, 두 벡터 사이의 각도의 코사인을 사용합니다.
- Sina Weibo: 중국의 대규모 소셜 미디어 플랫폼.
- Reddit: 익명으로 게시물을 작성하고 투표할 수 있는 인기 있는 영어 소셜 미디어 플랫폼.
- RSDD (Reddit Self-Reported Depression Diagnosis): Reddit에서 자가 보고된 우울증 진단 데이터 세트